이번에 진행한 프로젝트에서 나는 CloudType을 사용하여 NestJS 기반 서버를 무료로 배포하였다. 무료로 서버를 배포할 수 있다는 것이 정말 큰 장점이었지만, CloudType의 무료 티어의 경우 연속 실행 제한이 걸려 매일 오전 3~9시 사이 프리티어로 구동 중인 서비스는 자동으로 중지 상태로 변경되는 문제가 존재한다.

사실, 정지되는 것은 문제가 되지 않았다. 웹 사이트에 접속하는 사용자의 수도 많지 않았고, 오전 3~9시 사이에 접속하는 사용자는 더욱 낮을 것이라고 판단했기 때문이다. 그럼에도 일단 언제 중지될지 모르는 서버와 꺼져있는 서버를 재가동시키는 것을 깜빡하는 경우에 소중한 사용자의 데이터가 저장되지 못하는 일이 발생했다. 프로젝트 배포에서 가장 중요했던 사용자의 구매량과 버튼 클릭 수를 DB 서버에 저장하고 있었기에 이는 우리에게 나름 크리티컬한 문제가 되었다.
대응 방안
일단 초기 대응 방안은 그저 9시 이후에 CloudType 프로젝트 관리창에서 꺼져있는 나의 서버를 다시 켰다. 그런데 가끔 9시 이후에도 잘 켜져있다가 이후에 꺼지는 경우도 있었던 것으로 기억한다. 그래서, 언제꺼질지 몰라 지속적으로 확인했었다. 이는 너무 귀찮기도 했고 짜증나기도 했다. 그렇게 점점 서버 재가동을 놓치는 시간이 많아졌고, 서버는 잠들어 있는 시간이 더 길어졌다.
문제를 해결하기 위해, 아이디어를 구상해 보았다.
- 서버 중단 시, 내부 로직에 중단되기 직전 메일 등의 알림 기능을 구현
- 프론트엔드 단에서 서버의 응답이 정상적으로 오지않을 경우를 확인
- 헬스체크 서버를 구현 후 배포하여 주기적으로 확인
내 머리 속에 든 생각은 총 3가지였다. 우선 첫 번째 아이디어를 진행보았다. 서버 내부 메인 로직에 아래와 같은 코드를 넣어 서버가 다운될 시점에 로그 파일을 남길 수 있도록 진행했다.
process.on('exit', code => {
console.log(code)
logger.log({
level: 'error',
message: 'exit'
})
})
process.on('SIGINT', code => {
console.log(code)
logger.log({
level: 'error',
message: 'sigint'
})
})하지만, 서버가 중단되고 재가동 후 확인해본 결과 로그 파일은 생성되지 않았다. 그 원인에 대해 아직도 명확한 해답을 찾지는 못했지만 스스로 생각해본 결과 배포 시스템이 중단되는 것과 내부 로직은 관련이 없고, AWS처럼 시스템 중단 시 발생하는 이벤트가 존재할텐데 이를 활용해야 할 것 같다는 생각이 들었다. CloudType 공식문서에는 따로 나와있는 내용이 없었다.
두 번째 아이디어는 프론트엔드 단에서 내가 배포한 서버의 API를 호출했을 때, 응답이 정상적으로 오지않고 500 등의 에러를 응답할 경우에 알림을 보내는 기능을 생각해봤다. 사실 이 아이디어도 나름 깔끔하고 좋다고 생각했지만, 프론트엔드 개발자 분께서 본인의 코드를 건드는 것을 별로 좋아하지 않았고 그래서 일단 내가 스스로 해결해보려 노력해봤다.
마지막 아이디어를 지금 채택해 사용 중인데, 초기에 생각했던 것은 헬스체크 서버에 기존 서버의 헬스체크 Api를 스케줄링하는 기능을 구현해 배포하려고 했다. 생각해보니 그럼 서버가 두 개나 띄워져있는 것인데 이는 낭비라고 생각이 들었다. 그래서 찾은 방법이 ** Github Action으로 헬스 체크**하는 것이었다. Github Action으로 스케줄링을 걸어놓고 특정 시간에 한 번씩 서버의 상태를 확인하고, 이를 Slack으로 알림을 전송하는 것을 생각했다.
Github Action으로 헬스체크
github action에 등록한 헬스체크 기능을 코드로 먼저 보겠다.
name: health check
on:
# 스케줄링을 설정함 / 매분마다 한 번씩 이벤트를 트리거함
schedule:
- cron: '*/1 * * * *'
# workflow_dispath는 수동으로 이벤트를 트리거할 수 있도록 해주는 것을 의미함
workflow_dispatch:
jobs:
healthcheck:
runs-on: ubuntu-latest
steps:
# 지정한 서버에 대해 헬스 체크 진행
- name: Release API Health Check
uses: jtalk/url-health-check-action@v3
with:
github_token: ${{ secrets.GHP_TOKEN }}
url: ${{ secrets.RELEASE_URI }}
max-attempts: 3 # 시도 횟수
retry-delay: 1s # 시도 간격
# 트리거된 이벤트의 내용을 slack으로 전달
- name: action-slack
uses: 8398a7/action-slack@v3
with:
status: ${{ job.status }}
github_token: ${{ secrets.GHP_TOKEN }}
author_name: Github Action Health Check
fields: repo,message,commit,action,eventName,ref,workflow,job,took # 보낼 정보들
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEB_HOOK_URL }}
if: always() # 특정 조건에 상관없이 항상 실행
작성된 github action의 healthCheck 플로우는 다음과 같다. 이 후, slack의 incoming-webhook을 등록하여 진행하면 문제없이 서버의 healthCheck 기능이 정상적으로 작동된다. 덕분에 서버가 중단된 경우 Slack을 통해 알림을 받을 수 있게 되었고, 귀찮게 내가 한번씩 접속해서 서버가 중단되었는지 확인하지 않아도 알 수 있게 되어 너무 편하다.
| 서버 정상 작동 | 서버 중단 시 |
|---|---|
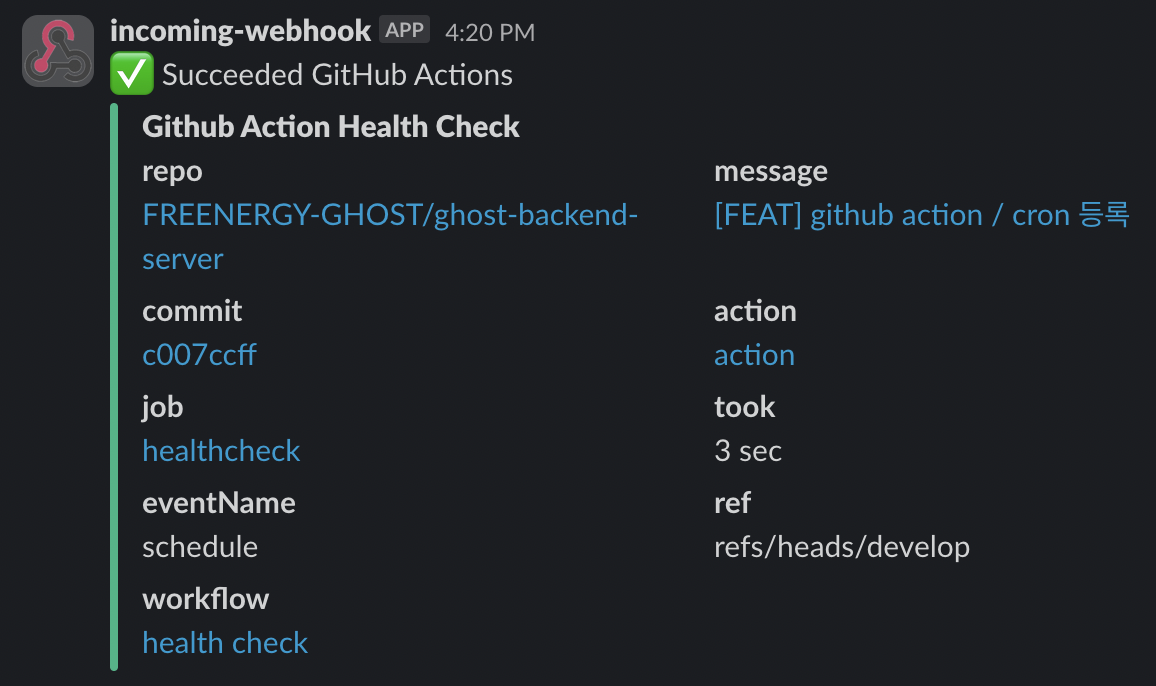 |
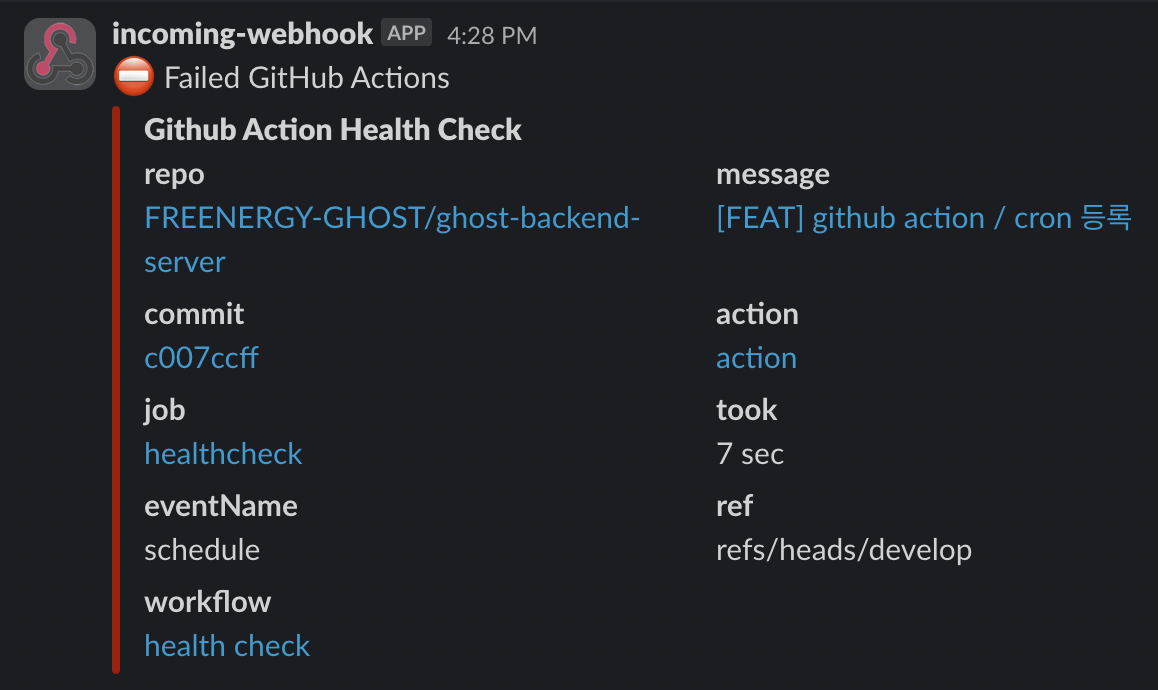 |

발생한 문제들
- Github Action에서 발생하는
"Resource not accessible by integration"문제 발생 -> github token을 넣어주면 해결 가능 "The process '/usr/bin/git' failed with exit code 1"문제 발생 -> healthCheck할 서버의 url이 정상적인 응답을 보내는지 확인 후 설정